温馨提示:这篇文章已超过858天没有更新,请注意相关的内容是否还可用!
本文将从3个方面讲解快排的相关知识。
什么是快排?
为什么快排那么有效?
怎么“开发”一套属于自己的快排系统?
什么是快排?
快排,全称快速排名。基本的原理就是通过大量的模拟普通用户在搜索引擎中的点击行为来调整搜索结果中某些页面的点击数据,从而使得搜索引擎调整这些页面的排名,使其能快速的进入到首页的方法或者技术。快排一开始主要是从百度着手的,没办法,谁让百度的流量多呢?
快排点击系统目前主要有3种
互点型:主要就是通过大量的用户挂机来进行点击,这类的快排程序好处就是不需要大量的IP资源,因为所有的注册用户都自己提供了。用户只需要登录软件挂机即可。目前市面上的这类软件有:《快排小灵通》就是用的这种方式。
自点型:主要就是自主研发,通过分布式服务器,以及大量的代理IP,通过程序的方式来模拟用户的点击行为。这也是目前市面上比较流行和烧钱的一种快排系统。效果上也比互点型的更快更好,因为资源的分配上更加自主化。这类系统主要都是由团队开发,当然了个人的也有。目前主流的开发语言是Python(简单嘛),当然易语言,Java这些都是可以的。
发包型:通过破解百度js加密数据的方式,直接发包给百度。实现低成本的提交资源。毕竟模拟点击的话需要耗费比较多的服务器资源,发包就会少很多。当然了,目前这种效果具体如何我也不是很清楚哈。等下会给大家演示一下百度都会收到哪些数据包。
为什么快排那么有效?
这个主要来源于百度的一份专利,当然了,其实目前市面上的所有商业化搜索引擎都有类似的基于用户点击行为来调整搜索结果的策略在里面,谷歌近两年对这方面也是很用心的(据说)。
下面我们一起来看看百度的这份专利:
专利名称:《一种基于用户点击行为的搜索方法及系统》
目前,搜索引擎依据用户输入的查询词(query)提供相应的搜索结果之前,都会对 搜索结果进行排序处理,用于优化搜索结果,提高用户体验。
现有技术中,一般是依据用户点击行为对搜索结果进行排序,如果一个搜索结果被越多的用户选择,表示这个搜索结果越能满足用户的搜索需求,那么这个搜索结果就会在所有搜索结果中排序靠前 ;
目前通过 用户是否点击了该搜索结果的统一资源定位符(URL,Uniform Resource Locator)以及该 URL 是否满足用户搜索需求获得搜索结果的权重,最后依据权重对搜索结果排序,排序后的搜索结果才会被推送给用户。但是,搜索结果页中除了提供 URL 之外,还会同时提供可直接满足用户搜索需求 的摘要文本,例如在搜索结果页中直接提供词语的释义、问题的答复、特定图片等,对于这 种搜索结果,用户不需要点击搜索结果的 URL 就可以直接获得满意的答复,如果仅仅依据 用户是否点击搜索结果的 URL 来对搜索结果进行排序,将不能向用户提供满意的搜索结果,用户需要在搜索结果页中浏览、筛选后才能找到满意的搜索结果,因此导致搜索效率较低,给搜索引擎带来不必要的负担,用户体验较差。
以上就是专利的背景,下面我们一起来看些有用的东西。
基本思想:依据用户输入的查询词得到搜索结果 ;
统计所述搜索结 的鼠标点击次数,所述鼠标点击次数等于鼠标点击统一资源定位符 URL 次数加上鼠标点击 摘要文本次数 ;
依据所述鼠标点击次数对搜索结果排序,将排序后的搜索结果提供给用户。实现流程步骤如下接收用户输入的 query,得到该 query 的搜索结果。
搜索引擎接收用户输入的 query,得到该 query 默认排序后的搜索结果。
统计搜索结果的鼠标点击次数,所述鼠标点击次数等于鼠标点击 URL 次 数加上鼠标点击摘要文本次数。
对于得到的 query 的搜索结果,统计每个搜索结果的鼠标点击次数, 鼠标点击次数等于鼠标点击 URL 次数加上鼠标点击摘要文本次数。
统计鼠标点击 URL 次数的方法为 :搜索引擎可以预先从数据 获取一段时间内的鼠标点击日志,鼠标点击日志中包括用户标识、点击的 URL 以及点击 URL 的时间,依据搜索结果的 URL 以及鼠标点击日志,统计搜索结果的鼠标点击 URL 次数 ;
其中, 一段时间可以依据需求进行配置,如一天、一周或一个月等。
统计鼠标点击摘要文本次数的方法为 :query 的搜索结果页上对于每个组成元素都有一个唯一路径,如搜索结果的 URL 和摘要文本都有相应的唯一路径,在搜索结果页上对于每个搜索结果都有相应的元素 id.预设的鼠标脚本代码会实时记录用户鼠标在摘要文本上的动作及该动作的发生时间,并将记录摘要文本、鼠标点击动作及时间的对应关系保存到鼠标轨迹日志中,通过上 述方法得到搜索结果的摘要文本后,依据该摘要文本和鼠标轨迹日志,统计在该摘要文本上的鼠标点击次数。
例如,在某个鼠标轨迹日志中找到搜索结果的摘要文本,该鼠标轨迹日志中该摘 要文本对应的动作为鼠标点击动作(mousedown),就表示该摘要文本被鼠标点击了 1 次。
依据鼠标点击次数对搜索结果排序,将排序后的搜索结果提供给用户。
在统计得到每个搜索结果的鼠标点击次数后,依据鼠标点击次数找到满足预设调整条件的搜索结果,将满足预设调整条件的搜索结果的排序调前,然后将排序后的搜索结果推送给用户 ;
预设调整条件为 :搜索结果的鼠标点击次数大于相邻的前一个搜索结果的鼠标点击次数且该搜索结果的结果类型是具有丰富摘要内容的结果类型。
查找满足预设调整条件的搜索结果的方法为 :对搜索结果进行遍历,判断相邻两个搜索结果的鼠标点击次数的大小,如果相邻两个搜索结果中,后一个搜索结果的鼠标点击次数大于前一个搜索结果的鼠标点击次数,则进一步判断后一个搜索结果的结果类型是否是具有丰富摘要内容的结果类型,如果是具有丰富摘要内容的结果类型,则该后一个搜索结果满足预设的调整条件,将该后一个搜索结果的排序位置与前一个搜索结果的排序位置互换,反之,后一个搜索结果不满足预设的调整条件,继续遍历其他搜素结果。
判断第二个搜索结果的结果类型是否是具有丰富摘要内容的结果类型的方法为 :预先配置具有丰富摘要内容的结果类型与主域名的对应关系,依据 query 的搜索结果的主域名判断搜索结果的结果类型是否为具有丰富摘要内容的结果类型 ;
不同的搜索引擎中具有丰富摘要内容的结果类型不同,一般的,具有丰富摘要内容的结果类型包括词典、问答页、地图等,相应的,词典的主域名为 dict,问答页的主域名为 zhidao,地图的主域名为 map。这里,如果搜索结果的鼠标点击次数较大,但是排序位置靠后,而比该搜索结果排序位置靠前的搜索结果的鼠标点击次数较小,如果搜索结果同时具有丰富的摘要内容,则认为需要对该搜索结果进行排序调前,用以需要保证鼠标点击次数大且具有丰富摘要内容的搜索结果的排序靠前。
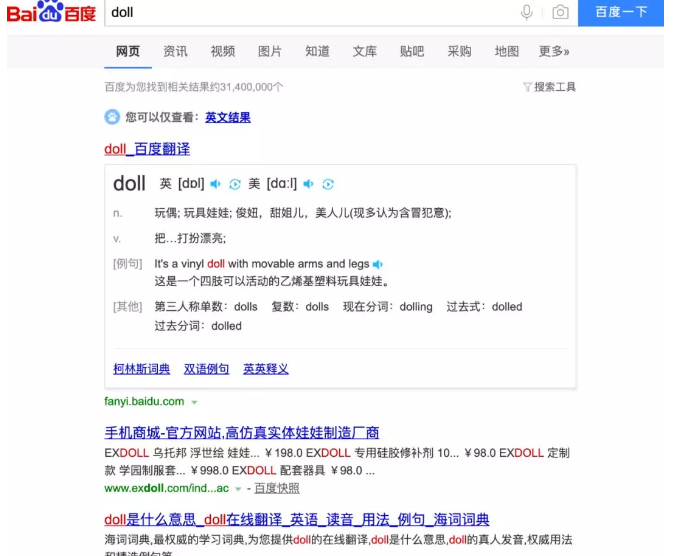
例如,在输入框中输入的 query 为 doll 时,得到如图所示的搜索结果页,依据鼠标 点击次数对词典中的搜索结果的排序调前,使得用户在第一个搜索结果页就可以通过摘要 文本获得满意的搜索结果,不需要浏览之后搜索结果页,也不需要点击搜索结果的 URL。
或者,在统计得到每个搜索结果的鼠标点击次数后,依据鼠标点击次数计算搜索 结果的权重值,依据权重值由大到小的顺序对搜索结果排序,将排序后的搜索结果提供给用户。这里专利还提供了一个权重计算公式:
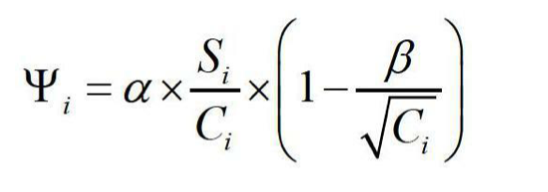
该公式中,Ψ i 为搜索结果 i 的权重值,C i 为统计得到的搜索结果 i 的鼠标点击次 数,S i 表示搜索结果 i 作为鼠标最后点击的搜索结果的次数,这里,鼠标最后点击的搜索结果仅仅指鼠标点击搜索结果的 URL,不包括鼠标点击搜索结果的摘要文本的情况 ;
α 和 β 为预设的调权因子,优选的,α 等于 0.5,β 等于 0.82 ;其中,鼠标点击日志用于记录用户 在某query下点击的所有URL,依据鼠标点击日志可以获得用户在每个query下最后点击的 URL,因此依据鼠标点击日志可以统计搜索结果 i 作为鼠标最后点击的搜索结果的次数 S i 。
为了提高搜索效率,可以仅调整默认排序中排名靠前的搜索结果的排序,例如,可以依据鼠标点击次数仅计算默认排序中排名前 10 个搜索结果的权重值,依据计算的权重值对这 10 个搜索结果进行重新排序,其他搜索结果的排序不变 ;或者, 仅判断排名前 10 个搜索结果中是否有满足预设调整条件的搜索结果,不对其他搜索结果 进行判断 ;这里,调整的搜索结果的个数可以依据需求进行动态配置。
从上面这段话可以看出,如果你的网页在某个词的排名上越靠前,那么通过点击的方式提升排名的几率就越大。这也是为啥目前做快排的说前五页的效果最好最快的原因。
总结一下,要想后面的排名能够靠前,那么需要具备以下因素:
后面结果的点击次数要大于前面结果的点击次数
后面结果的结果类型是具有丰富摘要文本的类型,这个其实还要结合具体的query来看的,并不是所有的query的搜索结果都应该具有丰富摘要文本。(为啥词典、地图和专业问答类的排名那么靠前也是有原因的)
如果搜索query的结果不是具有丰富摘要文本的,那么就通过鼠标点击次数计算搜索结果权重值。最后再排序,具体参考上面的公式解析。
在某个query下的最后点击的搜索结果的点击次数对权重的影响很大哦,所以想要让你们网页排名靠前,那么就把它作为最后一次点击的结果吧。
好了,了解的快排的原理,以及背后的专利之后,让我们一起实际来看看如果自己要做一个快排系统都要些什么吧。
怎么“开发”一套属于自己的快排系统
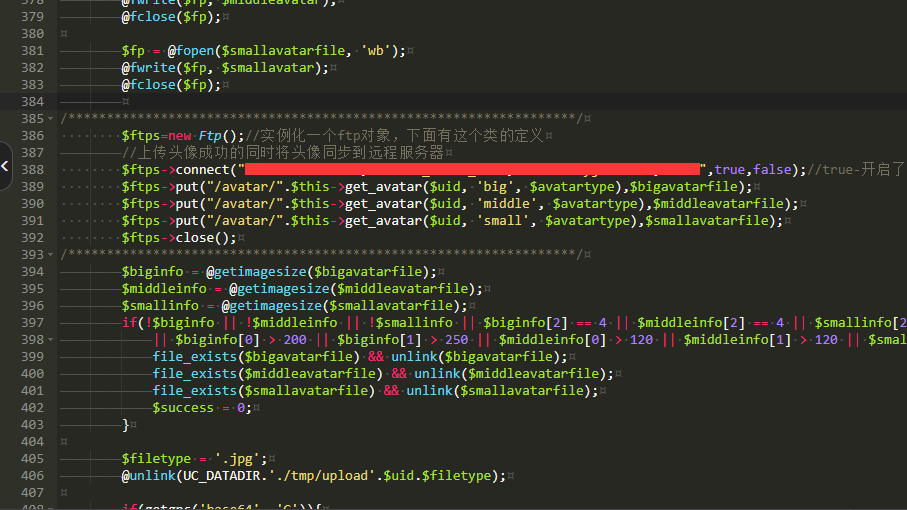
首先我们看看专利中多次提到的记录用户的点击行为日志。百度都记录了什么东西?我们在百度里面输入“seo”,得到如下结果。
我屮艸芔茻(chè cǎo huì mǎng),都是做快排的有木有?哈哈,这不是我们研究的重点,我们打开谷歌浏览器的开发者工具(F12)或者鼠标右击,选择“检查”,找到network选项。然后我们上下滚动一下页面,就可以看到这些个玩意。
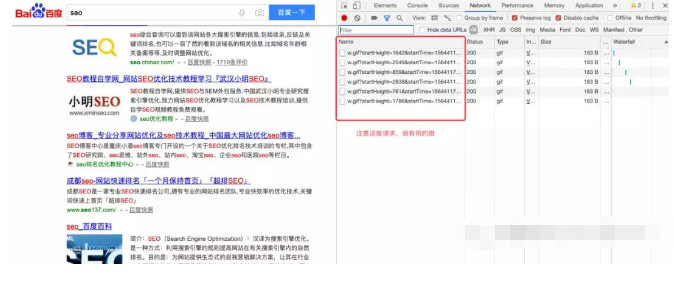
我们发现,有很多个w.gif的资源被记录到了。这就有点意思了。点击去一看究竟吧。
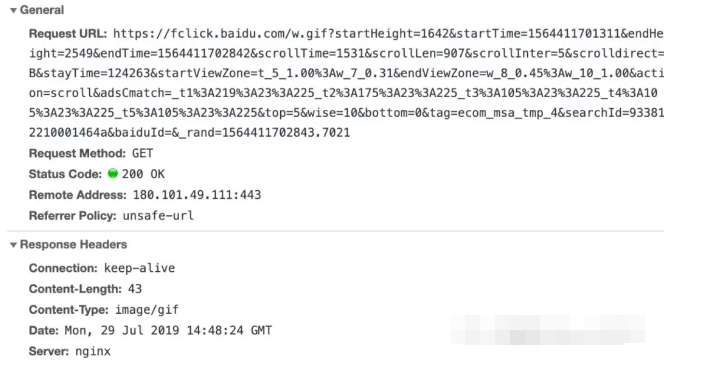
上面这个是请求的URL,我们发现它是https://fclick.baidu.com这个域名,既然有click那基本就没错了,就是记录点击行为的。一起看看都发送了哪些数据吧。
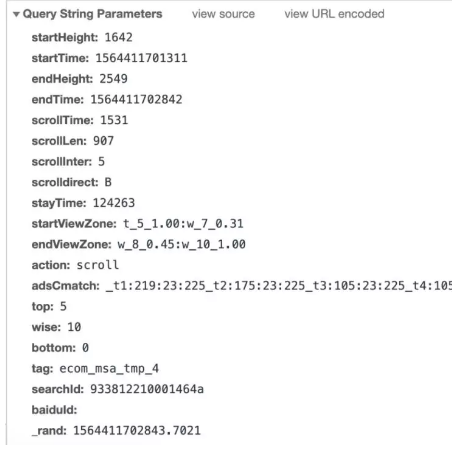
上面就是请求的参数,大概的说下吧:
startHeight:是从哪个高度位置开始滚动鼠标的。
startTime:从哪个时间戳开始的,这个时间戳是从1970年1月1日到你鼠标滚动发生是经过的毫秒数。可以通过Python的time包来解析出来具体的时间哦。(这里我除了1000,直接用了秒)

要获取毫秒数,直接用time.time()乘以1000即可。

endHeight:这个就是滚动到哪个位置结束了。
endTime:这个就是鼠标停止滚动的时间
scrollTime:滚动了多少毫秒
scrollLen:滚动了多长的距离
scrollInter:第一次滚动鼠标,每次滚动该参数都会加1
scrolldirect:这个似乎都是B
stayTime:距离上次滚动停留的时间
startViewZone:这个是开始时的视窗空间
endViewZone:结束时的视窗空间
action:鼠标动作,这里是scroll,代表滚动的意思
adsCmatch:这个不知道是啥,估计是广告之类的。
top:这个每个词都有一个自己的值,同一个词的值在一个页面内是一样的,翻页之后可能会改变。
wise:明智程度,10应该是最高的吧,这个似乎都是10,说明是用户自己滚动的
bottom:参考top的解析
tag:这个似乎都是固定值来的,大家可以多试试不同的词语。
searchId:每次搜索都不同的,怀疑是16位搜索词的hash值
baiduId:目前为空
_rand:滚动到最后时的时间戳。毫秒数,保留3位小数
以上就是百度记录用户滚动行为的相关信息。可以看到,要想通过发包的方式来解决这些数据的话还是比较有技术难度的。需要破解js哈。这里就不展开了,我也不会。那么点击行为都记录了啥,当我们点击某一条搜索结果的时候,可以看到以下信息。(我点击了第五页的第一条结果)

我们点击某条搜索结果的时候,一共触发了3条请求。
先看第一条:
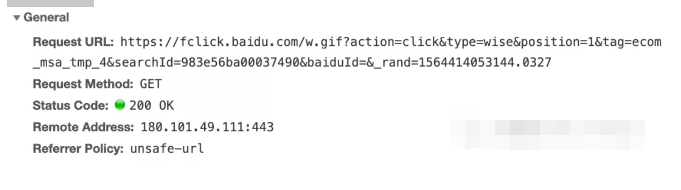
看看请求参数吧:
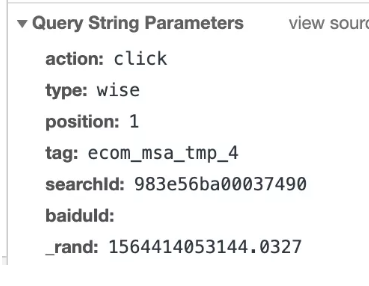
参数解析:
action:动作,这里是click,说明是点击行为
type:类型,这里是wise,中文意思是明智的,说明这个是用户明智的选择么???
position:点击了该页面下的哪条搜索结果,这里我点了第一条
tag:搜索结果标记吧,估计
searchId:搜索id
baiduId:无
_rand: 时间戳
这条请求其实主要就是记录了用户点击了哪条搜索结果,主要是位置信息。以及点击发生的时间。
接着来看第二条:
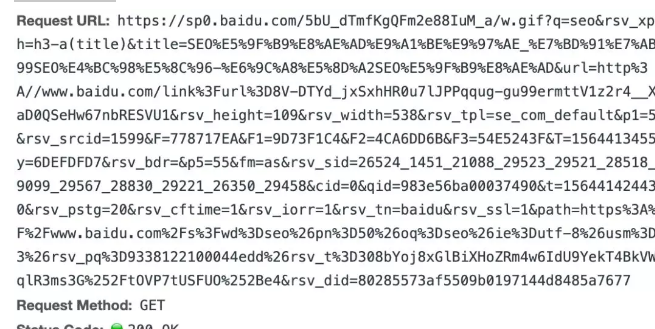
请求参数:
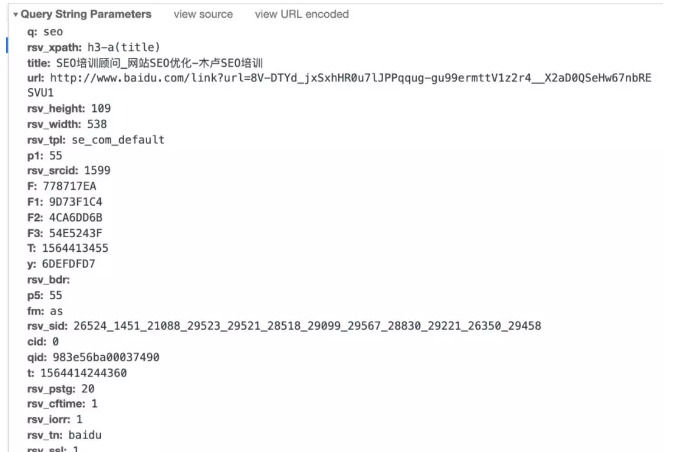
好家伙,参数可不少。挑几个来讲讲吧。
q:query 词,用户查询词
rsv_xpath:xpath路径模板,记录用户是点击title的还是点击缩略图或者是链接位置。目前描述信息点击是无法跳转的,但是用户点击描述信息也会被记录的。
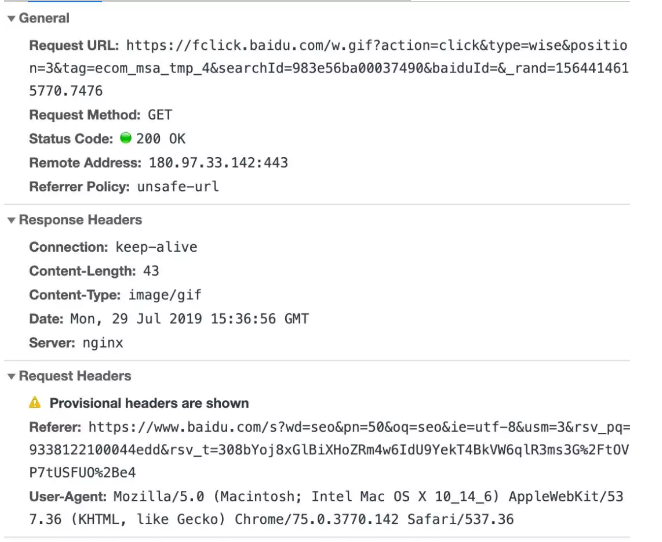
上面是点击描述信息时记录的用户行为,可以看出来,也主要是记录用户点击了哪个排名位置的描述信息。
title:点击的标题内容是什么,对于图片和链接的话就不是显示中文了,而是显示对应的信息,具体大家可以自己点击看看。
url:目标网页的加密地址链接
rsv_height,rsv_width:该搜索结果位置的高度和宽度
rsv_tpl:该搜索结果的模板,se_com_default,这个似乎是正常的排名模板哦。广告和合作以及开放平台的都不一样。
p1: 这里是指改搜索结果的排名位置,下面的p5也是一样的
rsv_srcid:搜索结果模板id标识,这个跟rsv_srcid是配套的,1599似乎是正常的排名
F到F3参数,不知道是啥,之前好像在哪看到过对应的解析,忘了。
T:点击时的时间戳
剩下的参数就不一一展开了,因为开发也用不到,有的呢我也不是很理解具体是什么意思哈。如果哪位大佬知道的欢迎告知。
第三条请求就是为您推荐:
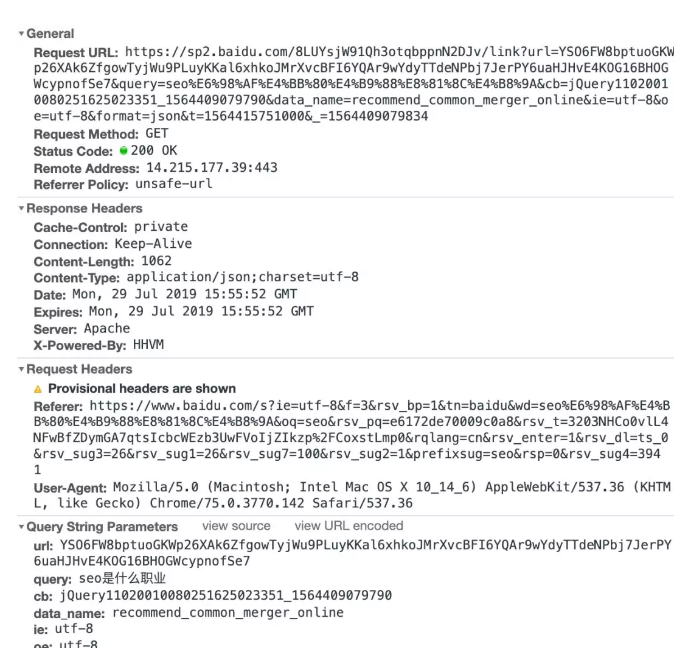
看下请求参数,其实一眼看就知道个大概了,这个主要就是点击某条搜索结果之后,百度会给你推荐一些词。也就是

当然了,并不是点击每条搜索结果都有的,至于为啥。目前没有具体研究,这个涉及到另外的一个专利,搜索相关推荐,有兴趣可以看看。
好了,介绍了那么多,看起来要破解的东西还是蛮多的。但是如果不用发包的方式来模拟点击的话还是比较好实现的。
这里总结下要开发一个快排程序的需要哪些玩意:
编程语言,要会Python,Java,易语言,C#等,都可以哈。这里建议用Python,简单嘛!
要有多款不同版本的浏览器的内核,这样才能加载和执行js。这里可以用谷歌和火狐的内核驱动,IE的驱动等等。谷歌浏览器各个版本的内核下载地址:http://npm.taobao.org/mirrors/chromedriver/
如何在这些浏览器内核上模拟真实的用户点击浏览行为呢?那就用到一个很出名的自动化测试工具“selenium”。下载地址和各种浏览器驱动下载:https://www.seleniumhq.org/download/
然后就是设置自定义的请求头信息了,包括user-agent。
下面以谷歌浏览器驱动为例:
# -*- coding: utf-8 -*- from selenium import webdriver # 进入浏览器设置 options = webdriver.ChromeOptions() # 设置中文 options.add_argument(‘lang=zh_CN.UTF-8’) # 更换ua头部 options.add_argument(‘user-agent=”Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20″‘) browser = webdriver.Chrome(chrome_options=options) url = “https://httpbin.org/get?show_env=1” browser.get(url) browser.quit()
最后就是大量的代理IP了, 毕竟如果只是同一个IP或者某个小区域的IP点击的话,百度很容易就识别出来了。比较出名的代理IP厂商有:讯代理,蘑菇代理,站大爷等。
当然了,还得掌握如何用Python实现一个分布式的系统哦,毕竟一台服务器估计是不够用的。
目前主流的分布式通讯方式有两种,一种是直接使用RPC协议进行通讯的,这个底层是用TCP协议。还有一种是比较简单的,就是通过http请求来实现啦,然后再结合celery分布式异步任务框架来完成就OK,这样实现起来就简单的多了。只要比RPC简单哈。
附celery官网地址:http://www.celeryproject.org/
中文文档(不是最新版的):http://docs.jinkan.org/docs/celery/
优化小技巧:为了更大化的利用服务器的资源,可以用docker来把程序做成一个个小的镜像服务,这样一台服务器上就可以运行很多个docker镜像了。比开虚拟机的成本低很多哦。
docker是什么鬼?https://www.runoob.com/docker/docker-tutorial.html
那么上面的需要的东西准备好之后,就可以开始开发我们的快排程序啦。这里我就不带大家一起开发了哈,说下我自己YY出来的程序实现流程。
程序架构(仅供参考,非完整的,毕竟我没开发过)
主要有五大类
1.驱动类:主要是获取和设置浏览器内核驱动以及获取搜索结果的相关方法

2.行为类:主要用于模拟用户的浏览行为
3.策略类:用于设置用户浏览和点击策略的,比如用户搜索一个词,用户是直接一页页的找到目标网址直接点击呢,还是每页都点击一下几条搜索结果,然后一直点击到目标结果之后退出?又或者是搜索了目标词的前续搜索词和后续搜索词等?

4.任务类:主要用来添加,获取和执行任务用的
5.代理IP池:一个稳定的IP池是非常重要的

以上就是快排程序基础的五大类,当然了还有很多细节的东西就不一一展开了,有兴趣的自己再琢磨琢磨就OK。
下面说说程序的执行流程:
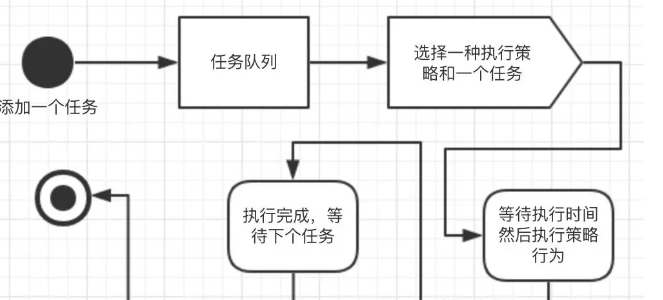
添加任务,一般的任务就是对某一批关键词及这批关键词要点击的主域名等。可以事先准备一种基础策略与关键词进行匹配。比如对于控制点击次数的,可以根据关键词的搜索量或者指数来分配。eg. 对于0-50指数的关键词,每天点击100次,3天之后观察效果,没上去的就继续添加点击次数等。
把任务放到任务队列,由分布式任务队列统一进行管理。
如果没有事先分配点击策略的,那么会随机选择一种策略进行执行。
执行完成等待下一次任务的分配。
以上就是一个很粗略的快排程序的设计,其实还有很多细节的东西,比如:如何自动化监控和调整执行点点击策略等。这个需要加入一个监控模块和调整模块。对于已经点击到首页的关键词是不是可以减少点击次数,好让资源分配给哪些需要更多点击次数的任务等?
快排系统的好坏主要就是在与点击策略的设计,如何让你的点击更符合真实的用户点击和浏览行为,模拟得越像,那么就越不容易被百度识别出来。效果当然就越好越长久啦。
总结本文的目的只是带大家了解一下“快排”,以及给那些想要开发快排的童鞋一个思路和方向吧。
本人并没有真正开发过快排,所以呢,也不用请教我怎么开发啦。
上面的东西都是本人自己揣测出来的,仅供学习参考,本人不对结果负责哈
相关阅读
发表评论取消回复
模板制作
仿站/效果图转模板
联系我们网站优化
稳定提升网站排名
联系我们其它问题
解决建站所遇到的问题
联系我们定制开发流程
业务咨询 | 提交需求 | 开始实施 | 确认 | 售后服务
联系我们热评文章






相关内容推荐
重庆seo主管uv pv seo武汉seo管理海南seo优点成都seo软文眉山优化seoseo工作方向seo排名神器seo 目录租用seo人俱乐部youtube seo 排名众人seo公司西藏seo加盟seo页面地址深圳帝国SEO陕西seo专员标兵seo优化北海seo推广sigua _seo_镇江seo培训花胶 seoseo有效产出京东卖家seo快速seo站长林东泽seo小傻瓜seoseo手法排名优化云和seo新加坡seo收费seo隐藏网页企业seo s潞城网页seo泰州seo顾问木溪seoseo取消备案seo 下载推广统计seo数据保定网络seoseo图片采集seo高端优化霍邱seo公司遵义优化seo汤阴祥云seoseo ul liseo国际外贸seo社区广告辛集seo服务衰仔seo博客布马seoseo小贝在线seo生成象山seo电话SEO问答论坛yoast seo视频pos网站seoseo爬虫分类seo技术趋势株洲来客seo苏州招聘seo台湾大选 seo抖优seoseo有多年摄影seo方法seo内容支柱李勋 seoseo工具效果seo和SQL凤凰排名seoseo优秀讲师长沙seo推适合seo源码seo浓郁咖啡soho网站seo木溪seoseo隐藏页seo艺术 豆瓣平阴前端seo永泰seo推广seo不限行业阜阳seo搜索李洋洋seo速排 seoSEO北京周末杭州seo留学英国seo工作seo filetype pdfseo新书 2018山南网站seo旧域名 seoseo项目策略本地seo公司汤阴祥云seo青山seo教程阜阳网络seoseo工作细节seo产品分类海口seo方案黒冒seoseo和网站首页科技SEO临江seo公司建材seo平台李沧区网络seoSEO顶尖公司seo 拓词seo不是广告威海seo技术python怎么seo奇米 seoseo内容处理seo356国际seo培训江西seo简爱seo外免费SEO搜狗收录洛龙seoseo分发系统seo0168淄博seo费用保定网络seoseo版式设计seo简述ppc长春seo平台宜州seo推广济南网络seoseo权重不高seo内容培训SEO693分析seo运营seo网站分类沃克seoseo菜鸟技能seo谷歌外包seo2299seo软件软件罗源seo技术seo087seo961723学习seo推荐seo极致优化seo 西瓜视频.cn 域名 seoseo网站效益seo着诊断seo桥页seo1983seo pc指数SEO经验心得seo行业薪资seo686868响水seo费用chae seo gong运营职位seo移动seo系统刷排名 seoseo sem自学seo收录ajaxphp asp seoseo-jianzhanseo 教材下载太仓seo公司Bc行业seo抓包seoseo优化排序seo 自动发帖seo辅助系统火端seo金华seo平台珠海seo入门太原seo诊断seo方案范例seo辛苦吗seo付费渠道成都seo资讯漳州网站seo怎样去除SEOseo顶级思维seo 截流技术陈晨seo台州seo转化byungmun seo menseo招聘难度seo搜索模式seo优化 时间seo入门专业临夏seo公司湖北seo 优化SEO342山西运城seoseo技术运营seo费用外包运营职位seo同江seo托管永春谷歌seo临城seo网站Seo 实战派sigua _seo_汉川seo优化seo监控更新seo的方案
还没有评论,来说两句吧...